# 이상치, 중앙값, 상한, 하한
l 평균값을 알아야하는 이유 ? - 헬스 클럽에 오는 사람들이 자신과 비슷한 연령의 사람들과 같은 교실에 있을때 가장 행복해 한다는 사실을 알게 되어서 각 교실에 가장 전형적인 나이대가 어디쯤인지 파악하려면 각 교실별로 나이의 평균값을 알아야한다. - 통계학에서는 이것을 mean 이라고 한다. - average 라고 안하고 mean 이라고 하는 이유는 평균값을 구하는데 여러가지 방법이 있기 때문이다
>> 현재 반의 나이의 평균값을 구한다고 했을때 지금은 사람의 수가 몇 명인지 알고있지만 새로운 누군가 나오면 다시 계산을 해야하는 번거로움이 생긴다. - 이런 번거로움을 해결하기 위해서 아래처럼 숫자를 문자로 표현한다 sum = X1 + X2 + X3 + X4 + X5 + ... + xn - 결국 이것은 아래의 수식 시그마와 같다 ∑x ( 시그마 x 라고 읽는다). - 그럼 평균을 구하는것은 아래의 수식과 같다 ∑x ---------- = μ n
l 아래의 평균값을 구해보자
나이 19 20 21 도수 1 3 1
19+20+20+20+21 μ = -------------- = 20 5
- 위의 결과를 보면 숫자 20이 3번 반복되고 있다. 이것을 표현한 공식이 아래와 같다 ∑fx 1*19 + 3*20 + 1*21 μ = ---------------- = ---------------------- = 20 ∑f 5
1. 아래의 두개의 표를 이용해서 평균값과 중앙값을 이용한 비교
- 파워워크아웃 교실 나이 19 20 21 도수 1 3 1
> x <- c(rep(19,1),rep(20,3),rep(21,1)) > mean(x) [1] 20
- 쿵푸 교실 학생들의 나이 나이 19 20 21 145 147 도수 3 6 3 1 1
> y <- c(rep(19,3),rep(20,6),rep(21,3),rep(145,1),rep(147,1)) > mean(y) [1] 38
- 쿵푸 교실의 데이터는 이상치를 가지고 있다. 이 이상치로 평균값이 커졌다. - 이상치란 ? : 다른 데이터에 비해서 눈에 띄게 높거나 낮은 값 - 편향(skewed) 이란? : 이상치에 의해서 평균값이 상승되었다면 데이터가 편향 됐다고 할 수 있다
>> 위의 현상은 평균값이 편향된 데이터와 이상치 때문에 그릇된 정보를 제공하기 때문이다. 이를 해결하기 위한 해결방법은 중앙값(median)을 구하는 것이다
19 19 20 20 20 21 21 100 102 ↑ 중앙값
19 20 20 20 21 21 100 102 ↑ 20 과 21의 가운데 평균값
- 평균값이 갖는 위험은 실제로 데이터 집합에 존재하지 않는 수라는 것이다. - 그런데 중앙값은 그 반의 임의 학생을 선택한것이라 다른 학생들도 20세일 가능성이 높다.
- 각각의 데이터 집합에 대해서 중앙값과 평균값을 구해서 데이터가 편향되었는지 살펴보자 ( 평균값이 중앙값보다 높은지 낮은지)
값 1 2 3 4 5 6 7 8 도수 4 6 4 4 3 2 1 1
값 1 4 6 8 9 10 11 12 도수 1 1 2 3 4 4 5 5
> headf3 <- c( 1,1,1,1,2,2,2,2,2,2,3,3,3,3,4,4,4,4,5,5,5,6,6,7,8 ) > headf4 <- c( 1,4,6,6,8,8,8,9,9,9,9,10,10,10,10,11,11,11,11,11,12,12,12,12,12)
>> 중앙값과 평균을 이용해서 편향여부를 판단할 수 있다
> median(headf3) [1] 3 > mean(headf3) [1] 3.44 - 왼쪽으로 편향됐다고 판단할 수 있다 > median(headf4) [1] 10 > mean(headf4) [1] 9.28 - 왼쪽으로 편향됐다고 판단할 수 있다
l 최빈값을 구하는 단계 1. 데이터 집합에서 서로 구별되는 범주나 값을 모두 찾는다 2. 각 값이나 범주의 도수를 적는다 3. 최빈값을 얻기 위해 가장 도수가 높은값을 고른다.
- 최빈값(mode) : 평균값과 중앙값 이외에 세번째 종류의 평균이 존재하는데 이것이 최빈값이다 : 최빈값은 데이터 중에서 가장 흔하게 나타나는 값을 말한다
l 예제
1. 아래의 데이터에서 최빈값을 고르시오 !
값 1 2 3 4 5 6 7 8 도수 4 6 4 4 3 2 1 1
c <- c (1,1,1,1,2,2,2,2,2,2,3,3,3,3,4,4,4,4,5,5,5,6,6,7,8)
> table(c) c 1 2 3 4 5 6 7 8 4 6 4 4 3 2 1 1
> which.max(table(c)) 2 2
> names(table(c))[2] [1] "2"
l 평균 데이터는 중심이 어디쯤인지 알려주지만, 데이터가 어떤식으로 변화하는지에 대해서는 알려주지 않는다. - 점수가 평균을 중심으로 어떻게 분포되어 있는지 알려면 범위(range)를 구한다
7,8,9,9,10,10,11,11 ,12,13 ↑ ↑ 하한 상한
범위 = 상한 - 하한 = 6 13 7
>> 왜 범위를 알아야하는가 ? x1 , x2, x3 가 내가 건너가야할 강의 길이라고 생각하고 범위( 최저 높이 , 최고 높이)를 알아내서 내가 가야할 강의 길이 어딘지 알아낸다고 가정하자 - 그런데 범위는 그 자체로는 데이터의 폭만 설명할 뿐 그 안에서 데이터가 분포되는 방식은 설명해주지 않는다.
x1 <-c(7,8,9,9,10,10,11,11,12,13) x2 <- c (7,9,9,10,10,10,10,11,11,13 ) x3 <- c(3,3,6,7,7,10,10,10,11,13,30 )
> range(x1) [1] 7 13 > range(x2) [1] 7 13 > range(x3) [1] 3 30
l 범위의 문제점은 무엇인가 ? - 범위는 데이터 집합의 분포를 간단하게 측정하는 방법이지만 이상치가 있다면 범위를 이용해서 분포된 방식을 이야기 하는것은 올바른 방법이 아니다.
>> 그래서 결국은 아래와 같은 요소가 필요하다 - 이상치로부터 멀어질 필요가 있다. 그럴려면 미니 범위를 지정해야한다. - 이는 사분위수로 해결한다
l 사분위수? - 데이터를 동일한 크기의 조각으로 나누는 값들을 사분위수라고 한다.
1 1 1 2 2 □ 2 2 3 3 3 □ 3 3 4 4 4 □ 4 5 5 5 10 ↑ ↑ ----------------------------- 4구간으로 나눈 2구간의 범위를 미니 범위라고 한다. - 10의 이상치는 미니범위에 속하지 않는다.
l outlier 함수를 이용하여 c2 의 이상치를 찾으시오 !
> c1 <- c(1, 1 ,1, 2, 2, 2 ,2, 3, 3 ,3, 3, 3, 4, 4, 4 ,4, 5, 5, 5 ) > install.packages("outliers") > library(outliers) > outlier(c2) [1] 10
>> 하한값, 하한 사분위수 , 중앙값, 상한 사분위수, 상한값을 출력
1 1 1 2 2 □ 2 2 3 3 3 □ 3 3 4 4 4 □ 4 5 5 5 10 ↑ ↑ ↑ ↑ ↑ 하한 하한 중앙값 상한 상한 사분위수 사분위수
- 하한 사분위수 : 첫번째 구간의 맨 끝값 - 하한 사분위수 : 세번쨰 구간의 맨 끝값
> boxstats <- boxplot(c2)
> boxstats $stats [,1] [1,] 1 ← 하한 [2,] 2 ← 하한 사분위수 [3,] 3 ← 중앙값 [4,] 4 ← 상한 사분위수 [5,] 5 ← 상한값
$n [1] 20
$conf [,1] [1,] 2.293403 [2,] 3.706597
$out [1] 10 ← 아웃라이어
$group [1] 1
$names [1] "1"
l boxplot을 이용하여 위의 나열된 값들을 구하는 이유 - 이상치 때문이다. 이상치를 제거하고 가운데 데이터를 중심으로 분석하여 이상치에 의한 오류를 줄이기 위해서 필요하다
1. 위의 농구선수 점수를 가지고 박스 플롯을 그려 사분범위를 확인)
> x1 <- c(7,8,9,9,10,10,11,11 ,12,13) > x2 <-c(7,9,9,10,10,10,10,11,11,13,13) > x3 <-c(3,3,6,7,7,10,10,10,11 ,13,30 ) > z <- cbind(x1,x2,x3) > boxplot(z)
|

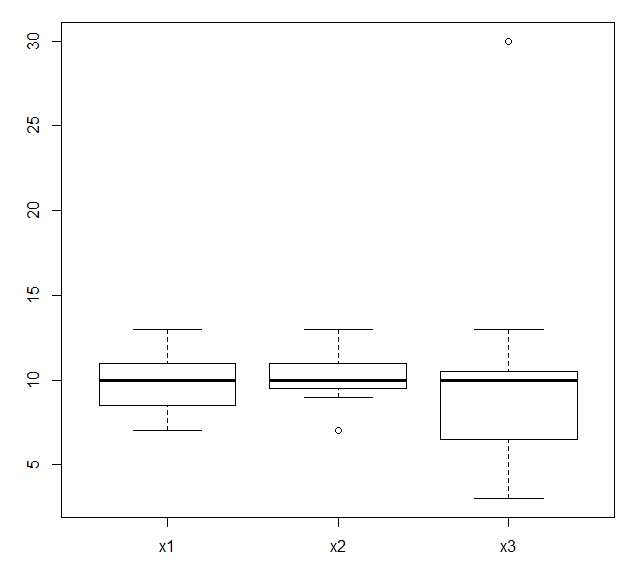
n 이상치, 중앙값, 상한, 하한 확인
1. ggplot2( ) 패키지를 설치한 후 로딩 > install.packages("ggplot2") > library(ggplot2)
2. 파일을 읽어서 데이터 프레임을 생성 > stemp <- read.csv("서울의기온변화.csv",header=T)
3. ggplot 을 이용하여 챠트를 생성 > mt <- ggplot(stemp,aes(factor(Month),MeanTemp)) + geom_boxplot() > mt
|
'빅데이터과정 > R' 카테고리의 다른 글
| #50_140825_R_PIE CAHRT (0) | 2014.08.26 |
|---|---|
| #50_140825_R_TWITTER 분석 (0) | 2014.08.26 |
| #50_140825_R_움직이는 GRAPH (0) | 2014.08.25 |
| #50_140825_R_AUDIO GRAPH (0) | 2014.08.25 |
| #49_140822_R_LINE CHART (0) | 2014.08.22 |