# R의 기본
l R 이란?
- 뉴질랜드 University of Auckland 대학의 Robert Gentleman 과 Ross Ihaka이며 1995년 개발함. R 은 데이터 분석을 위한 통계 및 그래픽스를 지원하는 자유 소프트웨어 환경이다. 그 뿌리는 벨 연구소에서 만들어진 통계 분석 언어 S에 근간을 두고있다.
- http://cran.nexr.com/ <-- R 다운로드 사이트
l R을 왜 쓰는가?
- R is free.
- data 분석을 위해 가장 많이쓰이는 통계 플렛폼이다.
- 복잡한 데이터들을 다양한 그래프로 표현할수있다.
- 분석을 위한 데이터를 쉽게 저장하고 조작할수있다.
- 누구든 유용한 패키지를 생성해서 공유할수있고
- 새로운 기능에 대한 전달이 아주 빠르다.
- 어떠한 os 에서도 설치가 가능하다 심지어 아이폰에도 설치할수있다.
l 환경설정
- 파일 > 작업디렉토리 변경 > data 압출파일을 압축 푼 폴더
> emp<-read.csv("emp.csv",header=TRUE) - 사원테이블인 emp.csv를 읽어들여서 emp 라는 테이블에 입력한다 > emp empno ename job mgr hiredate sal comm deptno 1 7369 SMITH CLERK 7902 1980-12-17 800 NA 20 2 7499 ALLEN SALESMAN 7698 1981-02-20 1600 300 30 3 7521 WARD SALESMAN 7698 1981-02-22 1250 500 30 4 7566 JONES MANAGER 7839 1981-04-02 2975 NA 20 5 7654 MARTIN SALESMAN 7698 1981-09-28 1250 1400 30 |
n EMP 테이블 원형 그래프
> boxplot(emp$sal, main="Salary Box Plot", ylab="Salary", col=c("yellow"))
> pie(emp$sal, main="Salary Pie Chart", labels=emp$ename, col=rainbow(15))
|


l 자료구조
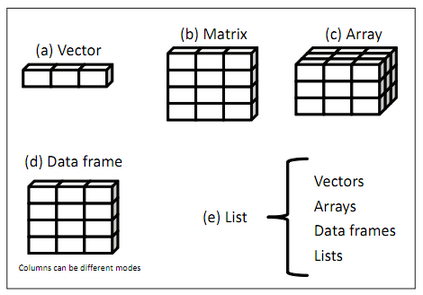
1. vector
- 같은 데이터 타입을 갖는 1차원 배열 구조
- R의 기본을 이루는 데이터 구조
- c() : combine value, seq() : sequence value 함수 사용
> a <- c(1,2,3,4,5) > a [1] 1 2 3 4 5
> d <- seq(1,20) > d [1] 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20
> f <- c(1:20); > f [1] 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20
> g <- seq(1,10,3) > g [1] 1 4 7 10
> rep(1:2,3) [1] 1 2 1 2 1 2 - 1부터 2까지 3번 반복 > rep(1:2,each=5) [1] 1 1 1 1 1 2 2 2 2 2 - 1부터 2까지 각각 5번씩 반복
> x <- NULL > x NULL > rm(x) > x 에러: 객체 'x'를 찾을 수 없습니다
|
2. matrix
- 같은 데이터 타입을 갖는 2차원 배열구조
- matrix 함수를 사용해서 vector 값과 표시할 행과 열을 지정
> c(1:9) [1] 1 2 3 4 5 6 7 8 9 > matrix(c(1:9)) - 행과 열의 개수를 지정하지 않으면 한 개의 열에 여러 개의 행을 표시 [,1] [1,] 1 [2,] 2 [3,] 3 [4,] 4 [5,] 5 [6,] 6 [7,] 7 [8,] 8 [9,] 9
> matrix(c(1:9), nrow=3) [,1] [,2] [,3] [1,] 1 4 7 [2,] 2 5 8 [3,] 3 6 9
> matrix(c(1:9), ncol=3) [,1] [,2] [,3] [1,] 1 4 7 [2,] 2 5 8 [3,] 3 6 9 |
3. data frame
- 각기 다른 데이터 타입을 갖는 컬럼으로 이루어진 2차원 테이블구조(DB의 테이블과 유사함)
- 서로 다른 컬럼은 데이터 타입이 다를 수 있음
- data.frame() 함수를 이용해서 생성하며 각 컬럼, 행의 이름을 지정 가능
> data.frame(x=c(1,2,3,4,5), y=c(2,4,6,8,10)) - 각기 다른 컬럼명을 지정가능하다 x y 1 1 2 2 2 4 3 3 6 4 4 8 5 5 10
> data.frame(col1=c(1,2,3,4,5), col2=c('a','b','c','d','e'), col3=c(6,7,8,9,10)) col1 col2 col3 1 1 a 6 2 2 b 7 3 3 c 8 4 4 d 9 5 5 e 10
> d <- data.frame(col1=c(1,2,3,4,5), col2=c('a','b','c','d','e'), col3=c(6,7,8,9,10)) > d col1 col2 col3 1 1 a 6 2 2 b 7 3 3 c 8 4 4 d 9 5 5 e 10 > d[2, c("col1","col2") ] col1 col2 2 2 b
|
4. array
- 같은 데이터 타입을 갖는 다차원 배열구조
- Matrix는 2차원 행렬이고 Array는 3차원 행렬
- array함수를 이용해서 3차원 배열 생성
> array(c(1:12), dim=c(3,4) ) [,1] [,2] [,3] [,4] [1,] 1 4 7 10 [2,] 2 5 8 11 [3,] 3 6 9 12 > array(c(1:12), dim=c(2,2,3) ) , , 1
[,1] [,2] [1,] 1 3 [2,] 2 4
, , 2
[,1] [,2] [1,] 5 7 [2,] 6 8
, , 3
[,1] [,2] [1,] 9 11 [2,] 10 12
|
5. list
- 서로 다른 데이터 구조(vector, data frame, array, list) 의 중첩된 구조
- list 함수를 이용해서 위의 데이터 구조를 중첩할 수 있다
> list(name="scott", sal=3000) $name [1] "scott"
$sal [1] 3000 |
6. factor
- 범주(값의 목록) 을 갖는 vector
- factor() 함수를 통해서 생성
- factor는 nominal, ordinal 형식 2가지가 존재한다
- Nominal은 level 순서의 값이 무의미하며 알파벳 순서로 정의
- ordinal은 level 순서의 값을 직접 정의해서 원하는 순서를 정의할 수 있다
> status <- c("Poor", "Excellent", "Improved") > status [1] "Poor" "Excellent" "Improved" > str(status) chr [1:3] "Poor" "Excellent" "Improved" > status <- factor(status) > str(status) Factor w/ 3 levels "Excellent","Improved",..: 3 1 2 > status [1] Poor Excellent Improved Levels: Excellent Improved Poor - default로 알파벳순으로 level이 정의된 것을 확인할 수 있다
> status <- factor(status, ordered=TRUE, levels=c("Poor","Improved", "Excellent") ) > status [1] Poor Excellent Improved Levels: Poor < Improved < Excellent - factor를 통해 level을 정의해준 것을 확인할 수 있다 |
n 벡터 색인을 사용해서 특정위치의 데이터를 검색
- [] : 색인
> x <- c("a","b","c") > x[1] [1] "a" > x[2] [1] "b" > x[3] [1] "c" |
n 벡터 각 셀에 이름 지정
- SQL의 컬럼과 같다
> x <- c(1,3,4) > names(x) <- c("scott","king","jones") > x scott king jones 1 3 4
> x[c("scott","jones")] scott jones 1 4 |
n 예제 활용
> x <- matrix(c(1:9), ncol=3) > x [,1] [,2] [,3] [1,] 1 4 7 [2,] 2 5 8 [3,] 3 6 9 > x[1,1] [1] 1 > x[2,1] [1] 2 > x[3,3] [1] 9
> matrix(c(1:9), nrow=3, ncol=3, byrow=TRUE) [,1] [,2] [,3] [1,] 1 2 3 [2,] 4 5 6 [3,] 7 8 9
|
>> dimnames, list 활용
> matrix(c(1:9), nrow=3, ncol=3, byrow=TRUE, dimnames=list(c("row1","row2","row3"),c("col1","col2","col3"))) col1 col2 col3 row1 1 2 3 row2 4 5 6 row3 7 8 9
> length(x) [1] 9 > ncol(x) [1] 3 > nrow(x) [1] 3
|
> emp$ename [1] SMITH ALLEN WARD JONES MARTIN BLAKE CLARK SCOTT KING TURNER ADAMS JAMES FORD MILLER JACK Levels: ADAMS ALLEN BLAKE CLARK FORD JACK JAMES JONES KING MARTIN MILLER SCOTT SMITH TURNER WARD > emp$sal [1] 800 1600 1250 2975 1250 2850 2450 3000 5000 1500 1100 950 3000 1300 3200
>> emp 테이블에서 sal 3000인 사원들의 이름과 월급을 가져오는 쿼리
> emp[emp$sal==3000, c("ename","sal") ] - emp$sal - 행 정보 - c("ename","sal") - 열에 대한 정보 ename sal 8 SCOTT 3000 13 FORD 3000
>> job이 SALESMAN인 사원들의 이름과 직업을 출력
[emp$job=='SALESMAN', c("ename","job") ] ename job 2 ALLEN SALESMAN 3 WARD SALESMAN 5 MARTIN SALESMAN 10 TURNER SALESMAN
|
'빅데이터과정 > R' 카테고리의 다른 글
| #48_140821_R_JOIN (0) | 2014.08.21 |
|---|---|
| #48_140821_R_GROUP 함수 (1) | 2014.08.21 |
| #47_140819_R_함수 (0) | 2014.08.19 |
| #47_140819_R_정렬 (0) | 2014.08.19 |
| #47_140819_R_연산자 (0) | 2014.08.19 |