# GROUP 함수
l 그룹함수
l 그룹함수 종류
- max, min, sum, mean, length, range
n 활용 예제
> car <- read.csv(“accident2.csv”,header=TRUE)
>> 전국에서 교통사고가 가장 많이 발생하는 지역은 어디인가?
> car[car$cnt==max(car$cnt),c("year","city","loc","cnt")] year city loc cnt 256 2009 서울 강북구 박내과옆 먹자골목 66
|
>> 직업, 직업별 최대월급을 출력하시오
> aggregate(sal~job, emp, max) job sal 1 ANALYST 3000 2 CLERK 3200 3 MANAGER 2975 4 PRESIDENT 5000 5 SALESMAN 1600
|
>> 부서번호, 부서번호별 토탈월금 출력
> aggregate(sal~deptno, emp, sum) deptno sal 1 10 8750 2 20 10875 3 30 9400 4 70 3200
> data.table(emp)[,sum(sal),by=deptno] deptno V1 1: 20 10875 2: 30 9400 3: 10 8750 4: 70 3200
|
>> 직업, 직업별 토탈월급을 출력하는데 직업이 SALESMAN 인 사원만 출력
> data.table(emp)[emp$job=='SALESMAN',sum(sal),by=job] job V1 1: SALESMAN 5600
|
>> 직업, 직업별 토탈월급을 출력하는데 직업이 SALESMAN 사원은 제외하고 토탈월급이 5000이상인 것만 출력
> data.table(emp)[!emp$job=='SALESMAN',sum(sal),by=job] job V1 1: CLERK 7350 2: MANAGER 8275 3: ANALYST 6000 4: PRESIDENT 5000 > x <- data.table(emp)[!emp$job=='SALESMAN',sum(sal),by=job] > x job V1 1: CLERK 7350 2: MANAGER 8275 3: ANALYST 6000 4: PRESIDENT 5000 > x[v1>=5000] 다음에 오류가 있습니다eval(expr, envir, enclos) : 객체 'v1'를 찾을 수 없습니다 - 대괄호 안에 소문자 컬럼값은 오류가 발생한다 > x[V1>=5000] job V1 1: CLERK 7350 2: MANAGER 8275 3: ANALYST 6000 4: PRESIDENT 5000
>> 위 직업별 토탈월급을 높은 것부터 낮은 것으로 정렬하여 출력
> library(doBy) 필요한 패키지를 로딩중입니다: survival 필요한 패키지를 로딩중입니다: splines 필요한 패키지를 로딩중입니다: MASS > orderBy(~-V1,x) job V1 1: MANAGER 8275 2: CLERK 7350 3: ANALYST 6000 4: PRESIDENT 5000
|
> car <- read.csv(“accident2.csv”,header=TRUE)
>> 전국에 교통사고중 최대 건수 출력
> max(car$cnt) [1] 66
>> 전국에서 교통사고가 가장많이 발생하는 지역
car[car$cnt==max(car$cnt),c("city")] [1] 서울 강북구
|
l 사전작업
>> 작업 디렉토리에 위 파일을 다운받는다
emp <- read.csv("emp.csv",header=TRUE) accident2 <- read.csv("accident2.csv",header=TRUE) crime <- read.csv("crime.csv",header=TRUE) attendance2 <- read.csv("attendance2.csv",header=TRUE) price <- read.csv("price.csv",header=TRUE) dept <- read.csv("dept.csv",header=TRUE)
|
n 그룹 함수 활용
>> 사원테이블에서 최대월급, 최소월급, 토탈월급, 평균월급, 인원수 출력
> data.frame(max(emp$sal),min(emp$sal), sum(emp$sal), mean(emp$sal), length(emp$sal) ) max.emp.sal. min.emp.sal. sum.emp.sal. mean.emp.sal. length.emp.sal. 1 5000 800 32225 2148.333 15
> x <- cbind(max(emp$sal),min(emp$sal), sum(emp$sal), mean(emp$sal), length(emp$sal) ) > names(x) <- c("maxsal","minsal","sumsal","avgsal","cnt") [1] "maxsal" "minsal" "sumsal" "avgsal" "cnt" > c(x) maxsal minsal sumsal avgsal cnt 5000.000 800.000 32225.000 2148.333 15.000
|
>> 사원테이블에 사원번호, 이름과 월급, 월급-평균월급을 출력
> data.frame(empno,ename,sal,sal-mean(sal)) empno ename sal sal...mean.sal. 1 7369 SMITH 800 -1348.3333 2 7499 ALLEN 1600 -548.3333 3 7521 WARD 1250 -898.3333 4 7566 JONES 2975 826.6667 5 7654 MARTIN 1250 -898.3333 6 7698 BLAKE 2850 701.6667 ……………………………………………
|
>> 자신의 월급이 사원 테이블의 평균월급과 1000이상 차이가 나는 사원들만 출력
> x <- data.table(empno,ename,sal,diff=sal-mean(sal)) > x[diff>=1000 | diff<=-1000,] empno ename sal diff 1: 7369 SMITH 800 -1348.333 2: 7839 KING 5000 2851.667 3: 7876 ADAMS 1100 -1048.333 4: 7900 JAMES 950 -1198.333 5: 9292 JACK 3200 1051.667
|
>> 직업, 직업별 인원수를 출력
> aggregate(empno~job,emp,length) job empno 1 ANALYST 2 2 CLERK 5 3 MANAGER 3 4 PRESIDENT 1 5 SALESMAN 4
> data.table(emp)[,length(empno),by=job ] job V1 1: CLERK 5 2: SALESMAN 4 3: MANAGER 3 4: ANALYST 2 5: PRESIDENT 1
> table(emp$job) ANALYST CLERK MANAGER PRESIDENT SALESMAN 2 5 3 1 4 - 가로로 출력 |
>> attendance2 출석부에서 본인 이름만 출력
attendance2[attendance2$Name=='이우람',]
|
>> attendance2 에서 본인의 지각, 결석, 출결 상황을 조회하시오
> a <- attendance2[attendance2$Name=='박솔훈',c(2:41)] > as.integer(a) [1] 8 8 8 8 8 8 8 8 8 8 8 8 8 8 8 8 8 8 8 8 8 8 8 8 8 8 8 8 8 8 8 8 8 8 8 8 8 8 8 8 > table(as.integer(a)) 0 7 8 5 5 30 - 0이 5번, 7이 5번, 8이 30번이 나온 것을 확인할 수 있다
>> 위 데이터를 이용해서 그래프 출력
> pie(table(as.integer(a)), col=rainbow(6))
> barplot(table(as.integer(a)),col=rainbow(6))
|
>> 가로 출력
> tapply(sal,job,sum) ANALYST CLERK MANAGER PRESIDENT SALESMAN 6000 7350 8275 5000 5600 > table(emp$job) ANALYST CLERK MANAGER PRESIDENT SALESMAN 2 5 3 1 4 > tapply(sal,deptno,sum) 10 20 30 70 8750 10875 9400 3200
>> 직업별, 부서번호별 토탈월급 출력
> tapply(sal,list(job,deptno),sum) 10 20 30 70 ANALYST NA 6000 NA NA CLERK 1300 1900 950 3200 MANAGER 2450 2975 2850 NA PRESIDENT 5000 NA NA NA SALESMAN NA NA 5600 NA
|
>> 입사한 년도별(4자리), 부서번호별 토탈월급을 가로로 출력
> yhiredate <- format(as.Date(emp$hiredate),"%Y") > tapply(sal,list(yhiredate,deptno),sum) 10 20 30 70 1980 NA 800 NA NA 1981 7450 5975 9400 NA 1982 1300 NA NA 3200 1987 NA 4100 NA NA
|
>> 년도별, 지역별, 사망자수의 합을 가로로 출력
> data.frame(year,city= dead,serious,slight) > tapply(dead,list(year, substr(accident2$city,1,2)),sum)
|
>> 최대, 최소, 평균, 각 컬럼별 카운트 횟수 등등 확인방법
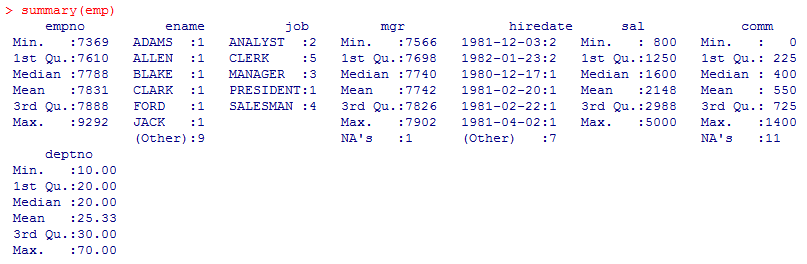
> summary(emp)
|


'빅데이터과정 > R' 카테고리의 다른 글
| #48_140821_R_COUNT (0) | 2014.08.21 |
|---|---|
| #48_140821_R_JOIN (0) | 2014.08.21 |
| #47_140819_R_함수 (0) | 2014.08.19 |
| #47_140819_R_정렬 (0) | 2014.08.19 |
| #47_140819_R_연산자 (0) | 2014.08.19 |