# GLOBAL ENQUEUE WAITS
l SQ enqueue에서 order와 noroder
- SQ enqueue : sequence에서 cache로 설정된 다음 sequence 값을 할당 받을 때 사용하는 enqueue

n RAC환경에서 sequence를 생성할 때 order, noorder 파라미터의 테스트
SQL#1> connect scott/tiger SQL#1> create sequence seq9 start with 1 increment by 1 maxvalue 100 cache 20 order; SQL#1> select seq9.nextval from dual; NEXTVAL ---------- 1 # 2번째 노드 SQL#2> select seq9.nextval from dual; NEXTVAL ---------- 2
SQL#2> select seq9.nextval from dual; NEXTVAL ---------- 3
|
SQL#1> connect scott/tiger SQL#1> create sequence seq11 start with 1 increment by 1 maxvalue 100 cache 20 noorder; SQL#1> select seq11.nextval from dual; NEXTVAL ---------- 1 # 2번째 노드 SQL#2> select seq11.nextval from dual; NEXTVAL ---------- 21
SQL#2> select seq11.nextval from dual; NEXTVAL ---------- 22 - 1번 노드에서는 1~20까지 cache에 올라와있고 2번 노드에는 21~40번까지 올라와 있기 때문에 2번 노드에서는 21번부터 시작하는 것을 볼 수 있다 - noorder로 하는것보다 order로 하는 것이 성능에는 좋지 않다 - 왜냐하면 order로 하게 되면 노드간에 어느 번호까지 출력했는지 알아내기 위해서 통신이 필요하다 - 여기서 노드간의 통신에 의해서 발생하는 대기 이벤트를 dfs lock handle 이라고 한다 - 그래서 RAC 환경에서는 order 보다는 noorder를 쓰라고 권장한다 |
l RAC 환경에서 파라미터 설정하는 경우의 수
- 1번이 가장 않좋은 경우이고 번호 순으로 좋지 않은 순서를 나타낸다
1. nocache : library cache lock 대기 이벤트
2. order + cache : dfs lock handle 대기 이벤트
3. noorder + cache 사이즈가 작을 때 : SQ enquene 대기 이벤트
4. noorder + cache 사이즈가 클 때 : SQ enqueue가 덜 발생
n SQ enqueue 대기 이벤트 발생 테스트(ADDM report)
>> order로 SQ enqueue 테스트
SQL#1> connect owi/owi SQL#1> alter sequence seq_sq_enqueue order; SQL#1> exec dbms_workload_repository.create_snapshot; SQL#1> @exec - SQ enqueue 발생 SQL#2> @exec - SQ enqueue 발생
SQL#1> exec dbms_workload_repository.create_snapshot; SQL#1> @?/rdbms/admin/addmrpt.sql
>> Sequence를 noorder로 변경 후 수행
SQL#1> connect owi/owi SQL#1> alter sequence seq_sq_enqueue noorder; SQL#1> exec dbms_workload_repository.create_snapshot; SQL#1> @exec - SQ enqueue 발생 SQL#2> @exec - SQ enqueue 발생 SQL#1> exec dbms_workload_repository.create_snapshot; SQL#1> @?/rdbms/admin/addmrpt.sql
- 위의 내용을 확인해보면 sequence cache misses 때문에 시간이 소비되고 있고 cache size를 늘리고 order를 사용하지 말라는 내용을 볼 수 있다 - 해결하기 위해선 아래처럼 다시 설정하면 된다 - alter sequence seq_sq_enqueue cache 100 nooder;
|

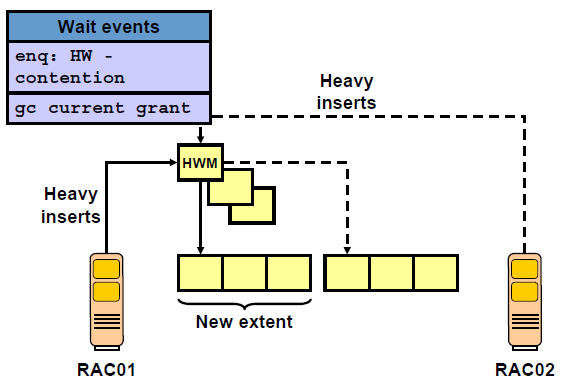
l HW enqueue
- high water mark enqueue
- 같은 테이블에 여러 노드의 여러 세션이 동시에 insert할 때 발생한다
- 여러 insert가 들어와서 공간이 부족할 때 하나의 세션이 lock을 걸고 HWM를 위로 올린다.
- 하나의 세션만 HWM을 올릴 수 있고 다른 세션들은 그 동안에 HW enqueue로 waiting 해야 한다
l 해결방법
- 테이블 스패이스의 속성을 변경하면 된다
- segment space management가 manual로 되어있다면 auto로 변경된 테이블 스패이스로 옮기면 된다
- 변경하면 free space에 대한 공간을 시스템이 자동으로 관리한다
- 아래의 명령어를 수행하여 manual인지 auto인지 파악하여 시스템이 자주 사용 하지 않는 auto로 설정된 테이블 스패이스에 문제가 되는 테이블을 옮긴다
SQL> select tablespace_name, segment_space_management from dba_tablespaces;
TABLESPACE_NAME SEGMEN ------------------------------ ------ SYSTEM MANUAL UNDOTBS1 MANUAL SYSAUX AUTO TEMP MANUAL UNDOTBS2 MANUAL USERS AUTO TS05 AUTO OWI_TBS AUTO TBS_GC_BUFFER_BUSY MANUAL
|
n hw enqueue 테스트
SQL#1> connect owi/owi SQL#1> exec dbms_workload_repository.create_snapshot; SQL#1> @exec - gc busy waits 발생 SQL#2> @exec - gc busy waits 발생
SQL#1> exec dbms_workload_repository.create_snapshot; SQL#1> @?/rdbms/admin/addmrpt.sql
SQL#1> select table_name from user_tables where tablespace_name='TBS_GC_BUFFER_BUSY'; - 조회하면 manual로 되어있는 TBS_GC_BUFFER_BUSY 테이블스패이스에 T_GC_BUFFER_BUSY 테이블이 들어있는데 이 테이블을 AUTO로 되어있는 OWI_TBS로 옮긴다 SQL> alter table t_gc_buffer_busy move tablespace owi_tbs;
|
l RAC 환경에서 truncate

- RAC 환경에서 양쪽으로 동시에 테이블 truncate하는 작업을 하면 다 느려지거나 멈춘다
- 이렇게 truncate 하는 경우는 DB를 이식시킬 때 이용하는데 여기서 나눠서 truncate를 하게 되면 양쪽간에 어떤 테이블을 truncate할 것인지에 대해서 통신이 필요하기 때문에 많은 부하가 걸린다
- 그래서 truncate를 RAC 환경에서 수행할 때는 한쪽에서 truncate를 시켜야 한다
l RAC 환경에서 튜닝 방법 정리
• Application tuning is often the most beneficial - SQL 튜닝이 가장 중요하다 • Resizing and tuning the buffer cache - 전송 받는 버퍼들도 있기 때문에 조정이 필요하다 • Reducing long full-table scans in OLTP systems - OLTP 환경은 짧은 transaction을 가지는 환경을 말하는데 이런 곳에서full table scan을 줄이라고 하고 있다 • Using Automatic Segment Space Management - HW enqueue를 예방한다 • Increasing sequence caches - SQ enqueue를 줄이기 위해서 cache를 늘린다 • Using partitioning to reduce interinstance traffic - partition wise 조인 • Avoiding unnecessary parsing - 과도한 cpu 사용을 줄이기 위해서 • Minimizing locking usage - lock을 최대한 자제하고 절대 변경되선 안되는 테이블은 아래와 같이 명령어를 수행한다 - lock table emp in exclusive mode; • Removing unselective indexes • Configuring interconnect properly |
'빅데이터과정 > RAC' 카테고리의 다른 글
| #46_140818_RAC_TAF (0) | 2014.08.18 |
|---|---|
| #45_140814_RAC_GC EVENT (0) | 2014.08.14 |
| #45_140814_RAC_CACHE FUSION (0) | 2014.08.14 |
| #44_140813_RAC_TUNING (0) | 2014.08.13 |
| #44_140813_RAC_DATAFILE 복구 (0) | 2014.08.13 |