# DATAFILE 복구
[rac1:+ASM1:/home/oracle]su - oracle Password: [rac1:yudb1:/home/oracle]sql SQL#1> select instance_name from v$instance; INSTANCE_NAME ---------------- yudb1 - 오라클 계정에서 sqlplus에 접속하면 yudb1이라는 instance로 접속한 것을 확인할 수 있다 SQL#1> exit [rac1:yudb1:/home/oracle]. .asm.sh [rac1:+ASM1:/home/oracle]sql INSTANCE_NAME ---------------- +ASM1 - .asm.sh 를 수행하면 ASM instance로 접속하는 것을 확인할 수 있다 |
[rac1:yudb1:/home/oracle]chmod 777 .asm.sh - .asm.sh 스크립트를 실행할 수 있는 권한을 최대로 허용 [rac1:yudb1:/home/oracle]. .asm.sh - .asm.sh 스크립트 수행 [rac1:+ASM1:/home/oracle]cat .asm.sh - .asm.sh 스크립트를 수행 export ORACLE_SID=+ASM1 export ORACLE_HOME=/u01/app/oracle/product/10.2.0/asm_1 - 위 스크립트를 수행하면 asm 커맨드로 들어갈 수 있는 조건이 성립된다 [rac1:+ASM1:/home/oracle]asmcmd ASMCMD> - 위처럼 asmcmd로 접속가능한 것을 확인할 수 있다 |
ASMCMD> cd data/yudb/datafile ASMCMD> ls SYSAUX.261.743034679 SYSTEM.259.743034645 TS05.268.855483839 UNDOTBS1.260.743034669 UNDOTBS2.263.743034691 USERS.264.743034699 ASMCMD> pwd +data/yudb/datafile ASMCMD> rm TS05.268.855483839 ASMCMD> ls SYSAUX.261.743034679 SYSTEM.259.743034645 UNDOTBS1.260.743034669 UNDOTBS2.263.743034691 USERS.264.743034699 - ts05 tablespace가 삭제된 것을 확인 할 수 있다 |
SQL#1> startup Total System Global Area 167772160 bytes Fixed Size 1218316 bytes Variable Size 130025716 bytes Database Buffers 33554432 bytes Redo Buffers 2973696 bytes Database mounted. ORA-01157: cannot identify/lock data file 6 - see DBWR trace file ORA-01110: data file 6: '+DATA/yudb/datafile/ts05.268.855483839' - datafile 6번이 없다는 메시지를 출력하는 것을 확인할 수 있다 SQL#1> select status from v$instance; STATUS ------------ MOUNTED - instance 상태를 확인하니 datafile이 없기 때문에 mount 상태까지 올라간다 SQL#1> select * from v$recover_file; FILE# ONLINE ONLINE_ ERROR CHANGE# ---------- ------- ------- --------------------------------------------- 6 ONLINE ONLINE FILE NOT FOUND 0 - 6번 파일이 존재하지 않는다는 것을 알 수 있다 |
l RAC 환경에서 controlfile 삭제 후 복구 방법
1. controlfile 백업
- 사용자 관리 백업
SQL> alter database backup controlfile to trace AS '/home/oracle/cre_con.sql';
- RAMN 백업
RMAN> configure controlfile autobackup on;
RMAN> backup datafile 5;
2. 현재 controlfile의 위치 확인
- SQL> select * from v$controlfile;
STATUS NAME IS_ BLOCK_SIZE FILE_SIZE_BLKS ------- -------------------------------------------------------------------------------------------------------- +DATA/yudb/controlfile/current.256.743034629 NO 16384 950 +FRA/yudb/controlfile/current.256.743034631 YES 16384 950 |
3. 양쪽 인스턴스 shutdown
4. asmcmd 창으로 접속해서 controlfile 삭제
- asmcdm는 디렉토리에 파일이 없으면 cd .. 명령어를 이용해서 뒤로 못간다
5. 1번 instance에서 startup
- SQL#1> startup
6. Controlfile 복구
- controlfile을 복구하려면 반드시 cluster_database 파라미터를 true에서 false로 변경하고 수행
- cluster_database을 false로 한다는 것은 반드시 하나의 인스턴스만 올라올 수 있다는 의미이다
- SQL> alter system set cluster_database=false scope=spfile sid='*';
7. Controlfile을 생성하는 스크립트(수정작업이 필요함) 수행
- 수정작업
$ vi cre_con.sql
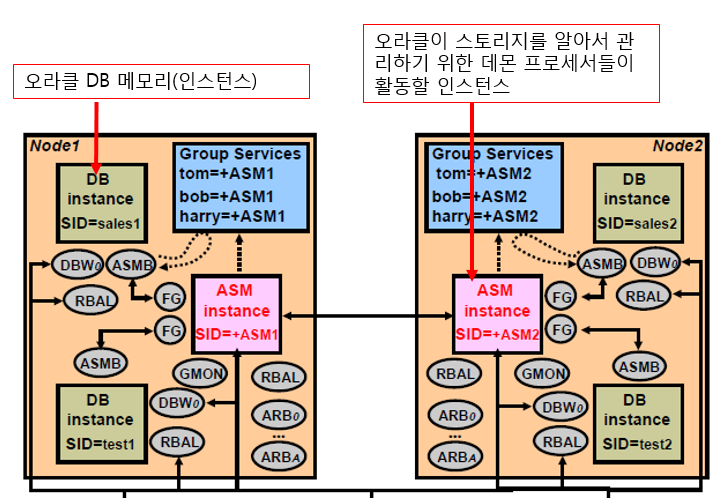
l colon을 이용해서 명령어를 수행한다 - 일일이 복사해서 하는 것 보다는 아래의 명령어를 이용해서 원하는 파일을 생성할 수 있다 :set nu :51,113 w c.sql - 51번부터 113번까지 소스를 c.sql 이라는 파일명으로 생성한다
l c.sql을 생성한 이후에 공백을 없애야 한다 - startup nomount 부분 삭제 - datafile 윗쪽에 주석을 포함한 공백부분 삭제
|
- asmcmd에서 controlfile 디렉토리가 삭제 됐기 때문에 만들어야한다
ASMCMD> cd data/yudb ASMCMD> mkdir controlfile ASMCMD> ls DATAFILE/ ONLINELOG/ PARAMETERFILE/ TEMPFILE/ controlfile/ spfileyudb.ora ASMCMD> exit [rac1:+ASM1:/home/oracle]asmcmd ASMCMD> cd fra/yudb ASMCMD> mkdir controlfile ASMCMD> ls ARCHIVELOG/ AUTOBACKUP/ BACKUPSET/ ONLINELOG/ controlfile/ |
- 스크립트 수행
SQL> shutdown abort
SQL> startup nomount
SQL> @c.sql
8. cluster_database 를 true로 설정
- SQL> alter system set cluster_database=true scope=spfile sid='*';
9. 1번 instance를 내린 후 다시 양쪽 instance를 startup
- 1번을 다시 내리는 이유는 scope가 spfile이기 때문에 다시 내렸다 올려야 한다
l Controlfile Autobackup 복구
1. controlfile 백업
- RMAN> configure controlfile autobackup on;
- RMAN> backup datafile 5;
: autobackup on 으로 설정하고 datafile 중에 아무파일이나 백업하면 자동으로 controlfile의 autobackup 파일이 생성된다
2. controlfile autobackup 위치 확인
RMAN> list backup of controlfile; List of Backup Sets ===================
BS Key Type LV Size Device Type Elapsed Time Completion Time ------- ---- -- ---------- ----------- ------------ ------------------- 20 Full 14.92M DISK 00:00:03 2014/08/13:14:19:35 BP Key: 20 Status: AVAILABLE Compressed: NO Tag: TAG20140813T141932 Piece Name: +FRA/yudb/autobackup/2014_08_13/s_855497972.270.855497975 Control File Included: Ckp SCN: 4807561 Ckp time: 2014/08/13:14:19:32 |
3. controlfile 위치 확인
SQL#1> select * from v$controlfile;
STATUS ------- NAME -------------------------------------------------------------------------------- IS_ BLOCK_SIZE FILE_SIZE_BLKS --- ---------- --------------
+DATA/yudb/controlfile/current.256.855491337 NO 16384 950
+FRA/yudb/controlfile/current.256.855491343 YES 16384 950 |
4. DB ID 확인
SQL#1> select dbid from v$database; DBID ---------- 3819339649 |
5. 양쪽 instance를 shutdown abort
6. asmcmd 창에서 controlfile 전부삭제
7. 1번 instance startup
8. RMAN 접속해서 복구
RMAN> restore controlfile from '+fra/yudb/autobackup/2014_08_13/s_855488827.311.855488829'; - +fra 디렉토리에 있기는 하지만 위 한번의 수행으로 controlfile 이 모두 복구된다 RMAN> ALTER DATABASE MOUNT; RMAN> RECOVER DATABASE; RMAN> ALTER DATABASE OPEN RESETLOGS; |
9. 2번 instance startup
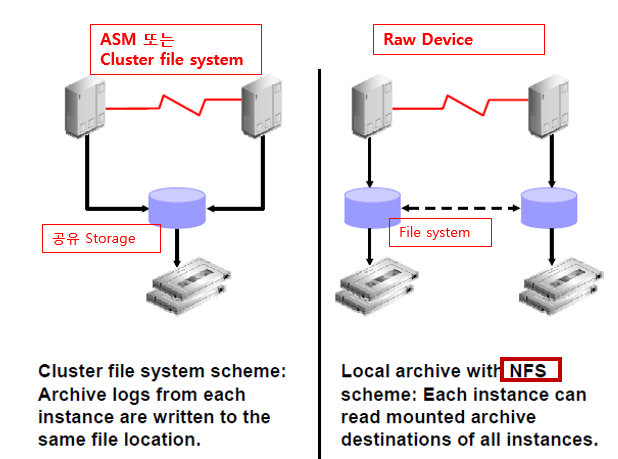
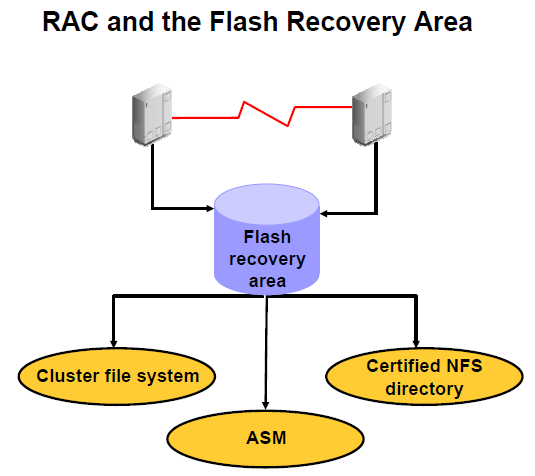
l ASM, Cluster file system이 아닌 raw device를 쓰는 환경일 때 복구 방법
- NFS(Network File System) 으로 구성하면 1번 노드에서 ls를 수행하면 2번 노드의 archive log file이 보인다
- 복구시 빠르게 복구 하려면 ASM이나 cluster filesystem 사용
l archive log file의 번호에 대한 파라미터

- %t : archive logfile 이 생성될 때 thread 번호를 의미
- %s : log sequence 번호
1. archive log file 파일 이름 생성 규칙
SQL#1> show parameter log_archive_format NAME TYPE VALUE ------------------------------------ ----------- ------------------------------ log_archive_format string %t_%s_%r.dbf - %t 부분을 보면 어느 인스턴스의 archive logfile인지 구분할 수 있다
SQL#1> select name from v$archived_log;
NAME -------------------------------------------------------------------------------- +FRA/yudb/archivelog/2014_08_13/thread_1_seq_21.316.855480071 +FRA/yudb/archivelog/2014_08_13/thread_2_seq_22.303.855481219 +FRA/yudb/archivelog/2014_08_13/thread_1_seq_22.283.855486081
|
l Snapshot controlfile
- controlfile에 백업받은 파일에 대한 이력정보가(백업시간) 포함된 파일
1. restore database 명령어는 아래 사항을 파악하고 있다는 의미이다
- rman으로 백업받은 백업본이 어디 있는지 알고 있다
- 백업본을 원본 디렉토리가 어디에 복원해야 하는지 알고 있다
2. controlfile은 백업파일 위치와 원래 백업해야할 디렉토리 위치가 포함되어 있다
3. autobackup을 키면 자동으로 controlfile을 백업하는데 이 백업 받은 controlfile들에 대한 이력정보를 snapshot controlfile에 저장되어 있다
4. snapshot controlfile 위치 확인
- RMAN> SHOW SNAPSHOT CONTROLFILE NAME;
/u01/app/oracle/product/10.2.0/dbs/scf/snap_prod.cf
5. snapshot controlfile 위치 지정
- RMAN> CONFIGURE SNAPSHOT CONTROLFILE NAME TO
'/ocfs/oradata/dbs/scf/snap_prod.cf';
l RAC 환경에서의 불완전 복구(time base)
- scott 유저를 drop 한 후에 scott 유저가 drop 되기 전 시점으로 복구하시오
- 장점
: 여러 노드에 있는 모든 리소스를 사용해서 백업을 할 수 있기 때문에 백업속도가 빠르다. 이 말은 여러 데이터들을 각각의 노드에게 분할해서 백업을 수행하기 때문에 한 개의 컴퓨터에서 백업을 할때 보다 시간이 빨라진다
: 서비스 친화도가 높은 data file들을 각 노드에서 각각 백업을 할 수 있기 때문에 백업속도가 빠르다.(비슷한 유형을 가지고 있는 node에서 각각 수행되기 때문에 친화도가 높다)
- 단점 : 복구 어드바이져를 사용못한다
RMAN> list failure;
RMAN> advise failure;
RMAN> repair failure;

1. full backup
2. 현재시간확인
SQL#1> select sysdate from dual;
SYSDATE ------------------- 2014/08/13:15:38:14 |
3. sys유저에서 scott 유저 drop
- SQL> drop user scott cascade;
4. 양쪽 instance를 shutdown immediate
5. 1번 instance만 mount 상태로 올린다
6. rman 접속해서 timebase 불완전 복구 수행
- RAMN> run {set until time '2014/08/13:15:38:14';
restore database;
recover database;
SQL "ALTER DATABASE OPEN resetlogs";
}
'빅데이터과정 > RAC' 카테고리의 다른 글
| #45_140814_RAC_CACHE FUSION (0) | 2014.08.14 |
|---|---|
| #44_140813_RAC_TUNING (0) | 2014.08.13 |
| #43_140812_RAC_전자지갑 (0) | 2014.08.12 |
| #43_140812_RAC_INSTANCE STOP START (0) | 2014.08.12 |
| #43_140812_RAC_UNDO TABLESPACE (0) | 2014.08.12 |