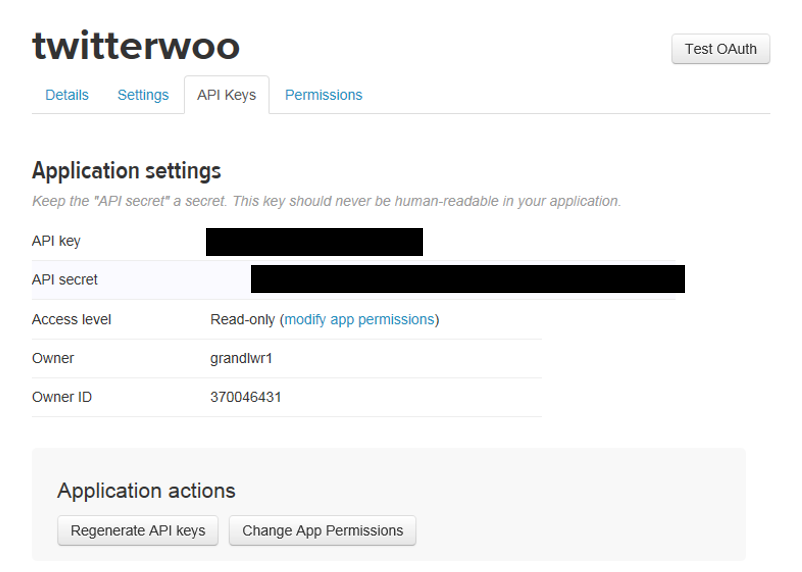
1. 아래 URL 접속 http://apps.twitter.com/app/new - 아래의 3가지 항목을 입력하고 동의한 후 create 클릭 
2. api key 확인 - 아래의 API key와 API secret 를 잘 저장해둔다 
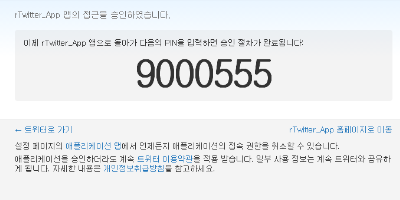
3. 아래의 명령어 순서대로 수행 > install.packages("twitteR") > install.packages("plyr") > install.packages("stringr") > install.packages("ggplot2") > library(twitteR) > library(ROAuth) > library(plyr) > library(stringr) > library(ggplot2) > download.file(url="http://curl.haxx.se/ca/cacert.pem", destfile="cacert.pem") > requestURL <- "https://api.twitter.com/oauth/request_token" > accessURL <- "https://api.twitter.com/oauth/access_token" > authURL <- https://api.twitter.com/oauth/authorize > APIKey <- "xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx" > APIsecret <- "xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx - 좀전에 기억해둔 apikey와 apisecret를 적어서 위 쌍 따옴표 사이에 적어서 수행한다 > Cred <- OAuthFactory$new(consumerKey=APIKey, consumerSecret=APIsecret, requestURL=requestURL, accessURL=accessURL, authURL=authURL) > Cred$handshake(cainfo = system.file("CurlSSL", "cacert.pem", package = "RCurl")) To enable the connection, please direct your web browser to: https://api.twitter.com/oauth/authorize?oauth_token=i5R6YnhthPM7DIknM9ktNujhBmaYsrsrnOIXprR9A When complete, record the PIN given to you and provide it here: 9406075 - 위에 URL을 들어가서 앱인증을 누르면 번호가 하나 나오는데 그 번호를 입력한다 

> save(Cred, file="twitter authentication.Rdata") > registerTwitterOAuth(Cred) [1] TRUE - TRUE면 정상동작을 의미한다 |
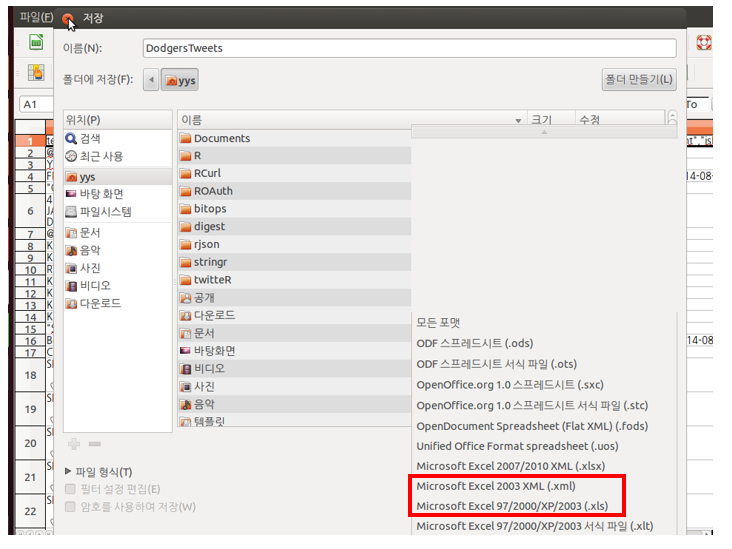
4. 원하는 검색어를 트위터에서 검색하여 csv 파일로 생성 - 류현진 : http://me2.do/xuYFVAEl > Dodgers.list <- searchTwitter('Dodgers', lang="en", n=500, cainfo="cacert.pem") > Dodgers.df = twListToDF(Dodgers.list) > write.csv(Dodgers.df, file='DodgersTweets.csv', row.names=F) - 추신수 : http://me2.do/FCTZaOgw > Rangers.list <- searchTwitter('Rangers', lang="en", n=500, cainfo="cacert.pem") > Rangers.df = twListToDF(Rangers.list) > write.csv(Rangers.df, file='RangersTweets.csv', row.names=F) - 윤석민 : http://me2.do/G0apHk1x > ioles.list <- searchTwitter('Orioles', lang="en", n=500, cainfo="cacert.pem") > Orioles.df = twListToDF(Orioles.list) > write.csv(Orioles.df, file='OriolesTweets.csv', row.names=F) 5. 함수 생성후 긍정과 부정 비교 n 함수 생성 score.sentiment = function(sentences, pos.words, neg.words, .progress='none') { require(plyr) require(stringr) # we got a vector of sentences. # plyr will handle a list or a vector as an "l" for us # we want a simple array ("a") of scores back, # so we use "l" + "a" + "ply" = "laply": scores = laply(sentences, function(sentence, pos.words, neg.words) { # clean up sentences with R's regex-driven global substitute, gsub(): sentence = gsub('[[:punct:]]', '', sentence) # gsub : http://me2.do/xzZFxvHu sentence = gsub('[[:cntrl:]]', '', sentence) sentence = gsub('\\d+', '', sentence) # and convert to lower case: sentence = tolower(sentence) # split into words. str_split is in the stringr package word.list = str_split(sentence, '\\s+') # sometimes a list() is one level of hierarchy too much words = unlist(word.list) # compare our words to the dictionaries of positive & negative terms pos.matches = match(words, pos.words) # match : http://me2.do/FHBclNZX neg.matches = match(words, neg.words) # match() returns the position of the matched term or NA # we just want a TRUE/FALSE: pos.matches = !is.na(pos.matches) neg.matches = !is.na(neg.matches) # and conveniently enough, TRUE/FALSE will be treated as 1/0 by sum(): score = sum(pos.matches) - sum(neg.matches) return(score) }, pos.words, neg.words, .progress=.progress ) scores.df = data.frame(score=scores, text=sentences) return(scores.df) } |
n 긍정 부정 단어와 csv 파일 불러오기 # Load sentiment word lists > hu.liu.pos <- scan("positive-words.txt", what='character', comment.char=';') Read 2006 items > hu.liu.neg <- scan("negative-words.txt", what='character', comment.char=';') Read 4783 items # Add words to list > pos.words <- c(hu.liu.pos, 'upgrade') > neg.words <- c(hu.liu.neg, 'wtf', 'wait','waiting', 'epicfail', 'mechanical') # Import 3 csv > DatasetDodgers <- read.csv("DodgersTweets.csv") > DatasetDodgers$text <- as.factor(DatasetDodgers$text) > DatasetRangers <- read.csv("RangersTweets.csv") > DatasetRangers$text <- as.factor(DatasetRangers$text) > DatasetOrioles <- read.csv("OriolesTweets.csv") > DatasetOrioles$text <- as.factor(DatasetOrioles$text) # Score all tweets > Dodgers.scores <- score.sentiment(DatasetDodgers$text, pos.words,neg.words, .progress='text') > Rangers.scores <- score.sentiment(DatasetRangers$text, pos.words,neg.words, .progress='text') > Orioles.scores <- score.sentiment(DatasetOrioles$text, pos.words,neg.words, .progress='text') > write.csv(Dodgers.scores,file='DodgersScores.csv',row.names=TRUE) > write.csv(Rangers.scores,file='RangersScores.csv',row.names=TRUE) > write.csv(Orioles.scores,file='OriolesScores.csv',row.names=TRUE) > Dodgers.scores$Team <- 'LA Dodgers' > Rangers.scores$Team <- 'Texas Rangers' > Orioles.scores$Team <- 'Baltimore Orioles' |
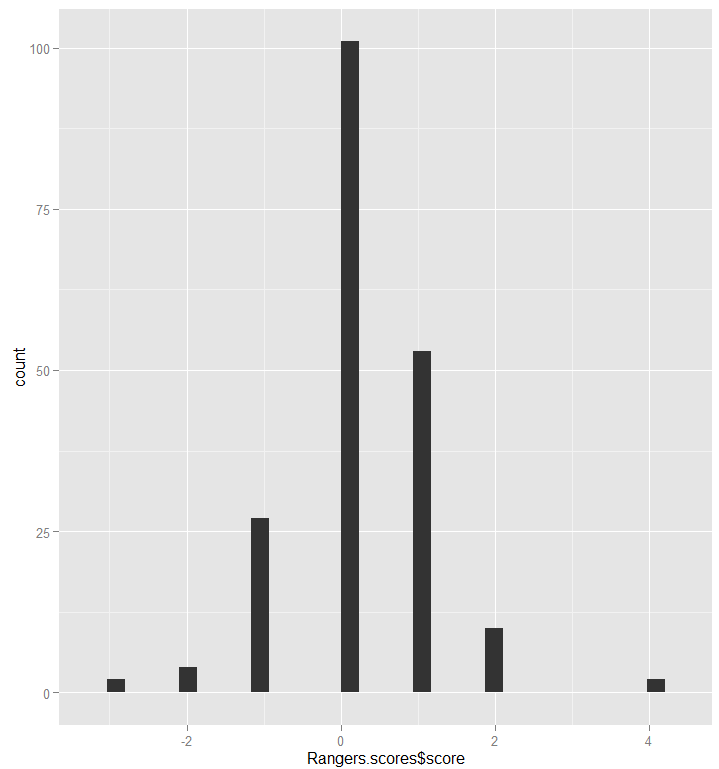
6. 긍정 부정 비교 그래프 생성 > hist(Rangers.scores$score, col="bisque")

> qplot(Rangers.scores$score)

> all.scores <- rbind(Rangers.scores, Dodgers.scores, Orioles.scores) > ggplot(data=all.scores) + geom_bar(mapping=aes(x=score, fill=Team), binwidth=1) + facet_grid(Team~.) + theme_bw() + scale_fill_brewer()
|
|