728x90
# TUNING ADVISOR
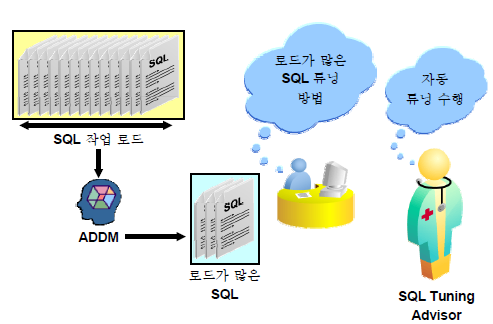

l SQL 프로파일 : SQL은 그대로 두고 실행계획만 최적의 실행계획으로 변경하는 기능
문제100. 튜닝전 SQL을 SQL tuning advisor 에게 맡겼을 때 결과
select /*+ optimizer_features_enable('10.2.0.3') merge(v) */ ename, sal, substr( totalsal,1,10) maxsal, substr(totalsal,11,10) minsal, substr(totalsal,21,10) sumsal from (SELECT ename, sal, (SELECT rpad(MAX(sal),10,' ') || rpad(MIN(sal),10,' ') || rpad(SUM(sal),10,' ') FROM EMP ) as totalsal FROM EMP) v; |
# SQL TUNING ADVISOR - with SQL profile : SQL tuning advisor가 제안하는 SQL 프로파일을 적용했을 때 효과 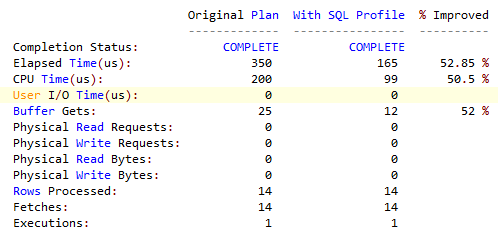  1- SQL Profile Finding (see explain plans section below) -------------------------------------------------------- A potentially better execution plan was found for this statement. Recommendation (estimated benefit: 51.97%) ------------------------------------------ - Consider accepting the recommended SQL profile. execute dbms_sqltune.accept_sql_profile(task_name => 'SQLGate2010:080614095909', task_owner => 'SCOTT', replace => TRUE); - 실행하면 실행계획이 추천하는 실행계획으로 바뀐다 - 반드시 한줄로 만들어 실행해야 한다  - advisor가 추천하는 execute를 실행하면 위처럼 실행계획이 바뀐 것을 확인할 수 있다 |
문제101. 아래의 SQL을 SQL tuning advisor에게 튜닝시키고 SQL 프로파일이 생긴다면 적용하시오
create table sales100
as
select *
from sh.sales;
create table products100
as
select *
from sh.products;
create table times100
as
select *
from sh.times;
# 튜닝 전 | |
select /*+ leading(t s p) use_nl(s) use_nl(p) */ p.prod_name, t.CALENDAR_YEAR, sum(s.amount_sold) from sales100 s, times100 t, products100 p where s.time_id = t.time_id and s.prod_id = p.prod_id and t.CALENDAR_YEAR in (2000,2001) and p.prod_name like 'Deluxe%' group by p.prod_name, t.calendar_year; 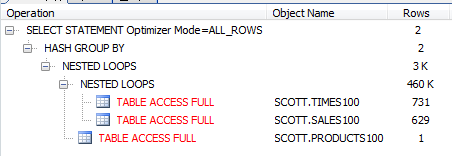 ------------- ---------------- ---------- Completion Status: PARTIAL COMPLETE Elapsed Time(us): 15777892 8043158 49.02 % CPU Time(us): 15382660 7848807 48.97 % User I/O Time(us): 6294998 96999 98.45 % Buffer Gets: 987266 4500 99.54 % 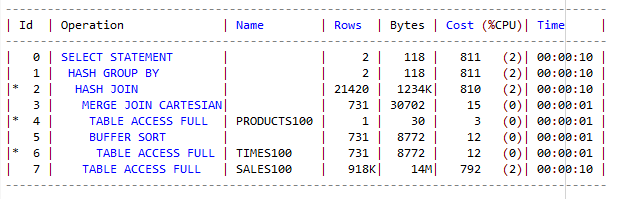 - 조인순서 : p -- t -- s - 조인방법 : p t : merge, t s : hash - advisor가 추천하는 순서대로 수행한다 | - 65초 수행 db block gets 0 consistent gets 5212183 physical reads 3240587 |
# 튜닝 후 | |
select /*+ leading(p t s) use_merge(t) use_hash(s) */ p.prod_name, t.CALENDAR_YEAR, sum(s.amount_sold) from sales100 s, times100 t, products100 p where s.time_id = t.time_id and s.prod_id = p.prod_id and t.CALENDAR_YEAR in (2000,2001) and p.prod_name like 'Deluxe%' group by p.prod_name, t.calendar_year;  | -7초 수행 db block gets 0 consistent gets 4496 physical reads 4433 |
문제102. 아래의 SQL을 SQL 튜닝 어디바이저에게 맡기시오
# 튜닝 전 | |
CREATE INDEX EMP_ENAME ON EMP(ename); SELECT ename, sal, deptno FROM EMP WHERE LOWER(ename)='scott'; 2- Restructure SQL finding (see plan 1 in explain plans section) ---------------------------------------------------------------- The predicate LOWER("EMP"."ENAME")=:B1 used at line ID 1 of the execution plan contains an expression on indexed column "ENAME". This expression prevents the optimizer from selecting indices on table "SCOTT"."EMP". Recommendation -------------- - Rewrite the predicate into an equivalent form to take advantage of indices. Alternatively, create a function-based index on the expression. - 다시 작성하거나 function 기반 인덱스를 만들라고 추천하고 있다 | db block gets 0 consistent gets 5212183 physical reads 3240587 |
# 튜닝 후 | |
CREATE INDEX EMP_ENAME ON EMP(ename); CREATE INDEX emp_ename_f ON EMP(LOWER(ename)); SELECT ename, sal, deptno FROM EMP WHERE LOWER(ename)='scott'; | db block gets 0 consistent gets 4496 physical reads 4433 |
문제103. 아래의 SQL을 SQL 튜닝하시오
# 튜닝 전 | |
select count(*) from SALES100 where prod_id in (select /*+ no_unnest no_push_subq */prod_id from products100 where prod_name like 'Deluxe%'); | - 7초 수행 |
# 튜닝 후 | |
select count(*) from SALES100 where prod_id in (select /*+ no_unnest push_subq */ prod_id from products100 where prod_name like 'Deluxe%'); | - 0초 수행 |
'빅데이터과정 > SQL TUNING' 카테고리의 다른 글
| #39_140806_TUNING_SQL 재작성 (0) | 2014.08.06 |
|---|---|
| #37_140805_TUNING_VIEW JOIN (0) | 2014.08.05 |
| #37_140805_TUNING_옵티마이저 힌트 총정리 (0) | 2014.08.05 |
| #37_140805_TUNING_바인드 변수와 실행계획 (0) | 2014.08.05 |
| #37_140805_TUNING_실행계획과 통계정보 (0) | 2014.08.05 |