728x90
# ORACLE MEMORY
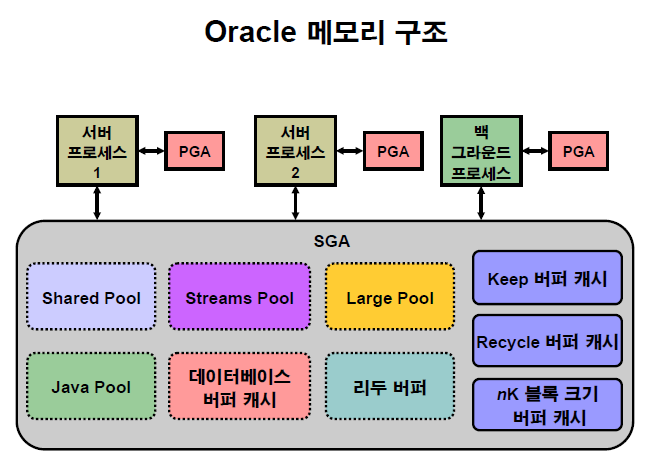
l db buffer cache를 효율적으로 사용할 수 있는 방법
1. 다중 버퍼풀을 구성해서 사용해라
: 테이블의 데이터를 메모리에 올릴 때 엑세스 되는 빈도에 따라서 다중 버퍼풀의 지정된 영역으로 데이터를 올리도록 하는 기능
- 자주 엑세스 하는 테이블(keep 풀) : 메모리에 오래 둠
- 자주 엑세스 하지 않는 테이블(recycle 풀) : 메모리에서 빨리 빠져나감
- 보통으로 엑세스 하는 테이블(default 풀) : 기본으로 관리되는 LRU 알고리즘
- buffer cache를 3개의 영역으로 나눈다

l 다중 버퍼풀 구성 방법
1. SQL> show parameter buffer
2. SQL> alter system set db_keep_cache_size=20m;
3. SQL> alter system set db_recycle_cache_size=10m;
4. SQL> select name, buffers from v$buffer_pool;
NAME BUFFERS -------------------- ---------- KEEP 2480 RECYCLE 1488 DEFAULT 7936 |
5. SQL> connect scott/tiger
6. SQL> alter table dept storage(buffer_pool keep);
7. SQL> alter table emp storage(buffer_pool recycle);
- dept 테이블은 keep 버퍼풀에 올림
- emp 테이블은 recycle 버퍼풀에 올림
8. SQL> select table_name, buffer_pool from user_tables;
TABLE_NAME BUFFER_ ------------------------------ ------- DEPART_TEST DEFAULT SYS_TEMP_FBT DEFAULT EMP RECYCLE DEPT KEEP SCOTT_TABLE_0722 DEFAULT EMP405 DEFAULT EMP400 DEFAULT EMP800 DEFAULT SALGRADE DEFAULT BONUS DEFAULT |
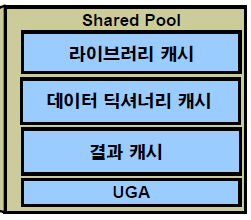
l shared pool 영역을 효율적으로 사용할 수 있는 방법
- shared pool 의 용도 : parsing을 최소화 하기 위한 메모리 공간
- 라이브러리 캐시 : SQL text, parse code, 실행계획
- 데이터 딕셔너리 캐시
: data 사전에서 읽은 정보.
: 같은 쿼리가 반복된다면 쉽게 찾을수 있도록 저장하고 같은 쿼리가 들어온다면 데이터 딕셔너리 캐시에서 읽어옴
- 결과 캐시 : result_cache 힌트를 사용한 SQL
- UGA : shared server 구조에서 세션의 정보
l select 문의 처리과정 3가지
1. parsing : SQL - 기계어
2. execute : 검색
3. fetch : 결과를 client 에게 전달
l result cache 란
- 한번 수행한 쿼리 또는 PL/SQL 함수의 결과값을 resurlt cache에 저장해뒀다가 다음번에 똑 같은 데이터를 요청하며ㄴ result cache에서 결과를 리턴해서 수행속도를 빠르게 하는 11g의 새로 나온 오라클 메모리
l result cache 사용 테스트
1. SQL> select /*+ result_cache */ ename, sal
from emp
where ename='SCOTT';
2. SQL> col tpye for a8
3. SQL> col name for a50
4. SQL> select type, name, namespace, scan_count
from v$result_cache_objects
where type='Result';
- result cache에 들어있는 SQL을 보는 쿼리
TYPE NAME NAMES SCAN_COUNT ---------- -------------------------------------------------- ----- ---------- Result select /*+ result_cache */ ename, sal SQL 0 from emp where ename='SCOTT' - 다시한번 똑 같은 쿼리가 들어오면 result cache에서 가져온다 |
l Result cache 제약 사항
1. result cache에 올린 데이터를 수정하면 result cache에서 그 데이터는 사라진다
2. data dictionary와 temporary table은 result cache에 못올린다
3. sequence의 nextval도 result cache에 못올린다

n SQL> select ename,sal from emp
where ename='SCOTT';
- 위 쿼리를 수행하면 쿼리 자체는 shared pool에 올리고 결과는 버퍼캐시에 올라간다.
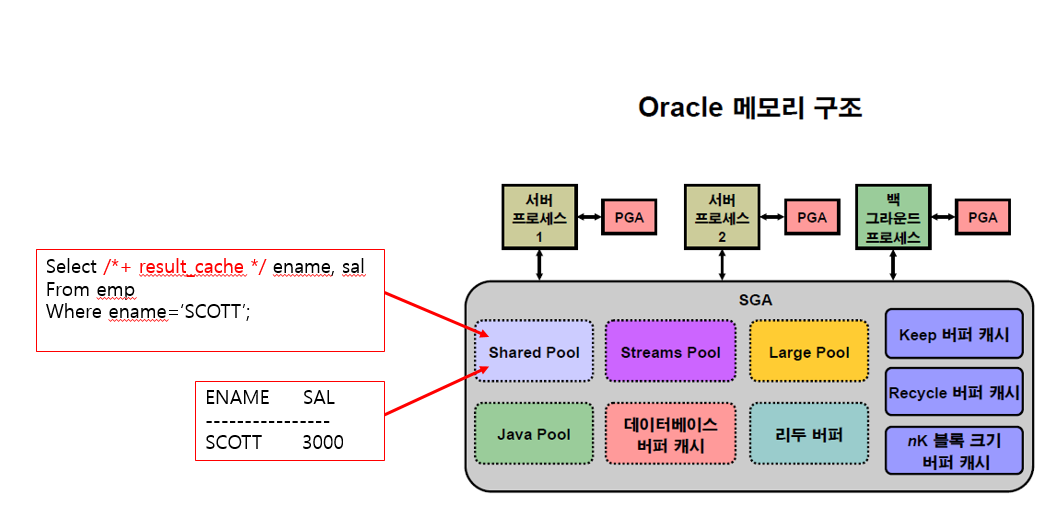
n 힌트를 쓰면 쿼리와 결과값 모두 shared pool 에 저장된다.
- 그 이유는 버퍼캐시까지 가는 시간을 줄이고 한곳에서 해결하기 위해서이다
'빅데이터과정 > WORKSHOP 2 ' 카테고리의 다른 글
| #30_140724_WSHOP2_LARGE POOL (0) | 2014.07.25 |
|---|---|
| #30_140724_WSHOP2_SHARED POOL (0) | 2014.07.25 |
| #29_140723_WSHOP2_AUTOMATIC DIAGNOSTIC REPOSITORY (0) | 2014.07.23 |
| #29_140723_WSHOP2_FLASHBACK ARCHIVE (0) | 2014.07.23 |
| #29_140723_WSHOP2_FLASHBACK QUERY (0) | 2014.07.23 |