728x90
# WORKSHOP
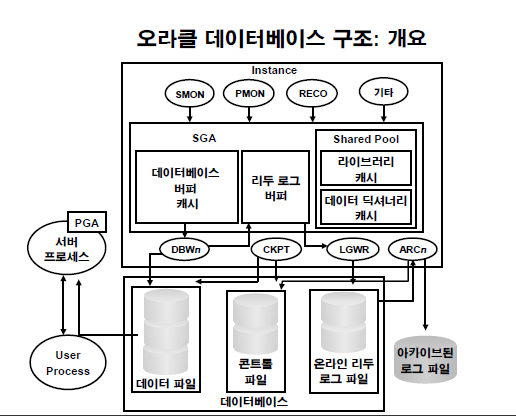
l 오라클 DB의 구조
1. database + instance (memory)
- 오라클 database 내의 3가지 파일 : data file, control file, redo log file
2. data file : data가 저장되어 있는 파일
- select file_name FROM dba_data_files;
3. control file : db를 control 하기 위한 파일(DB의 구조정보)
- 파일들의 위치와 이름, 상태정보
- SELECT NAME FROM v$controlfile;
4. redo log file : DB의 변경사항을 적어놓는 파일.
아래의 명령어가 log file로 들어감
장애 발생이 복구하기 위한 파일
- DML문 : insert, update, delete, merge
- DDL문 : create, alter, drop, truncate, rename
- DCL문 : grant, revoke
- TCL문 commit, rollback, savepoint
- SELECT member FROM v$logfile;
l 백그라운드 프로세서
- DBWR(Database Writer.) : 데이터베이스에 있는 버퍼 캐쉬에 있는 변경사항들을 datafile에 내려쓰는 역할
- LGWR(log writer) : redo log buffer 의 내용을 redo logfile에 내려쓰는 데몬. update delete 등등 변경사항을 내려받음
- CKPT(CheckPoint Process) : 메모리와 DB 간에 내용을 맞추는 데몬. 메모리의 내용의 변경사항을 주기적으로 DB에 반영하도록 이벤트 발생. 장애가 일어날 경우에 대비해서 기록함
- ARCH(Archive process) : redo log file을 따로 백업본을 생성하는 프로세서
l 오라클 DB 외부파일 3가지
1. Archive log file : redo log 파일의 복사본
- SELECT NAME FROM v$archived_log;
- archive log file 이 생성되려면 아카이브로그 모드로 되어 있어야 한다.(DB 모드 확인 명령어 : archive log list)
SQL> connect sys/oracle as sysdba
Connected.
SQL> archive log list
Database log mode No Archive Mode
Automatic archival Disabled
Archive destination USE_DB_RECOVERY_FILE_DEST
Oldest online log sequence 63
Current log sequence 64
- archive mode로 변경하는 방법
shutdown immediate
startup mount
alter database archivelog;
alter database open;
archive log list;
l 오라클 인스턴스 중요한 3가지 메모리
1. DB buffer cache : data file 에서 읽은 data file의 복사본이 저장되어 있는 메모리 영역
2. redo log buffer : DB의 변경사항(DML,DDL,DCL,TCL)
3. shared pool
확인 방법
SELECT sql_text FROM v$sql
WHERE sql_text LIKE 'select object_name%';
- SQL 문
- 실행계획
- 실행코드(Parse tree -> 기계어)
- shared pool 에 SQL에 올려놓는 이유는 : 다음번에 똑 같은 문장이 실행되었을 때 parsing 과정을 생략하기 위해서
4. background process
- DBWR(database writer)
- LGWR(LogWriter)
- CKPT(checkpoint process)
- Arch(archive process)
l select 문의 처리과정
select empno, ename from emp where empno = 7788;
1. parsing : SQL을 기계어로 변환, 문법검사와 의미검사(emp 테이블이 있는지 조회)를 수행한다.
의미검사 : select table_name from dba_tables where table_name=’EMP’ 를 이용해서 테이블이 있는지를 조회
대단히 많은 시간이 걸리기 때문에 파싱정보(SQL문, 실행계획, 실행코드)를 shared pool 에 올린다
다음번에 똑 같은 문장이 돌아오면 파싱과정을 생략하기 위해서
2. execute : 데이터 검색(메모리에서 먼저 데이터가 있는지 찾아보고 없으면 DB에서 찾아서 메모리로 올려놓는다)
3. fetch : 찾은 결과 데이터를 서버에서 클라이언트에게 전달
4. 서버프로세서가 parsing, execute, fetch를 수행
l 오라클의 메모리는 2가지 영역
1. SGA(System Global Area) : 여러 서버 프로세서들이 공유해서 사용하고 있는 메모리 영역
- shared pool
- DB buffer cache
- redo log buffer
2. PGA(Program Global Area) : 서버 프로세서들의 개별 메모리 영역
- 정렬작업을 하는 메모리 영역
order by
union
intersect
minus
create index 스크립트
- (3) select ename, sal
- (1) from emp
- (2) where job=’SALESMAN’
- (4) order by sal desc;
'빅데이터과정 > WORKSHOP 1 ' 카테고리의 다른 글
| #19_140709_WSHOP_깔끔하게 출력하는법 (0) | 2014.07.15 |
|---|---|
| #19_140709_WSHOP_장애복구 (0) | 2014.07.15 |
| #19_140709_WSHOP_SHUTDOWN 옵션 (0) | 2014.07.15 |
| #17_140708_WSHOP_INSTANCE (0) | 2014.07.15 |
| #16_140707_WSHOP_데이터베이스 구조2 (0) | 2014.07.15 |